Two-stream CNNs for video action recognition
Using advanced techniques in spatial and temporal stream convolutional neural networks (CNN) in the Keras framework, we’ve successfully achieved on the state-of-the-art results for the UCF-101 action recognition dataset.
View code »
We build neural networks for video classification by using the spatial and temporal stream CNNs under the Keras framework. We achieved the state-of-the-art results for the UCF-101 action recognition dataset.
We use UCF101 rgb frames as the spatial input data. We use split #1 for all of our experiments. We use the preprocessed tvl1 optical flow dataset as the motion input data. Please refer to our GitHub repo for detailed steps on setting up the above datasets.
Results
We show the prediction accuracies for the spatial-stream CNN and the temporal-stream CNN and the fused network respectively, and compare with those of the state-of-the-art implmentation.
| Simonyan et al | Ours | |
|---|---|---|
| Spatial | 72.7% | 73.1% |
| Temporal | 81.0% | 78.8% |
| Fused | 85.9% | 82.0% |
Methods
We implement spatial-stream CNN and temporal-stream CNN and fusion by following Simonyan et al. The following figure shows the model architecture. 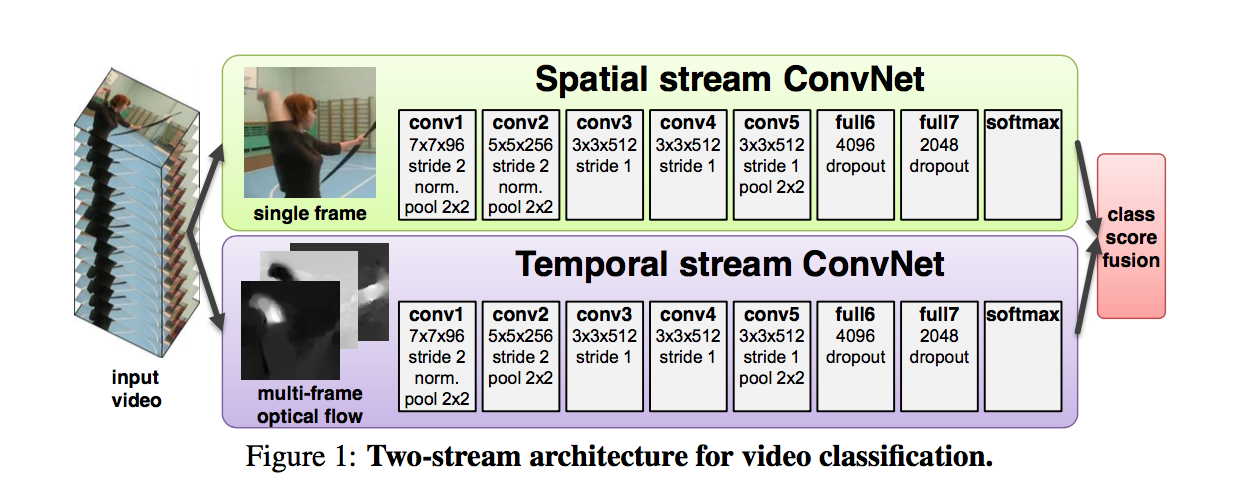
Spatial-stream CNN
We classify each video by looking at a single frame. We use ImageNet pre-trained models and transfer learning to retrain Inception on our data. We first fine-tune the top dense layers for 10 epochs and then retrain the top two inception blocks.
Temporal-stream CNN
We train the temporal-stream CNN from scratch. In every mini-batch, we randomly select 128 (batch size) videos from 9537 training videos and futher randomly select 1 optical flow stack in each video. We follow the reference paper and use 10 x-channels and 10 y-channels for each optical flow stack, resulting in a input shape of (224, 224, 20).
Multiple workers are utilized in the data generator for faster training.
Data augmentation
Both streams apply the same data augmentation technique such as corner cropping and random horizontal flipping. Temporally, we pick the starting frame among those early enough to guarantee a desired number of frames. For shorter videos, we looped the video as many times as necessary to satisfy each model’s input interface.
Testing
We fused the two streams by averaging the softmax scores.
We uniformly sample a number of frames in each video and the video level prediction is the voting result of all frame level predictions. We pick the starting frame among those early enough to guarantee a desired number of frames. For shorter videos, we looped the video as many times as necessary to satisfy each model’s input interface.
Talks
- W. Dong, A. Ozcan, Two-stream convolutional networks for action recognition in videos, Neuroscience Theory Club, Department of Neurobiology, the University of Chicago. (Invited; April 2018)