Scaling Distributed Training of Flood-Filling Networks on HPC Infrastructure for Brain Mapping
Imagine deciphering the complexities of the brain’s neural network, one cell at a time. In this project, we’ve tackled this monumental task by enhancing the efficiency of training the flood-filling network (FFN) architecture, a state-of-the-art neural network in segmenting structures from voluminous electron microscopy data. By implementing cutting-edge distributed training techniques and optimizing batch sizes on the supercomputers, we’ve not only significantly reduced training time but also achieved remarkable segmentation results, paving the way for a deeper understanding of the brain’s intricate workings.
Read paper »
View code »
Mapping all the neurons in the brain requires automatic reconstruction of entire cells from volume electron microscopy data. We visualize 2D segmentation of a single slice and 3D volume segmentations of neurons in the images below.
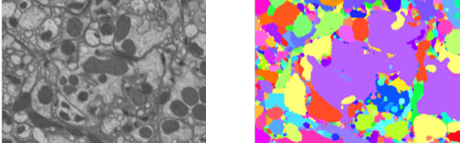
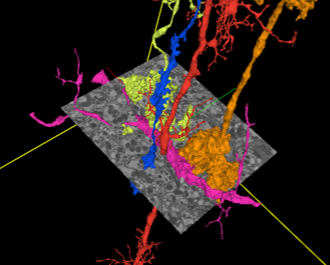
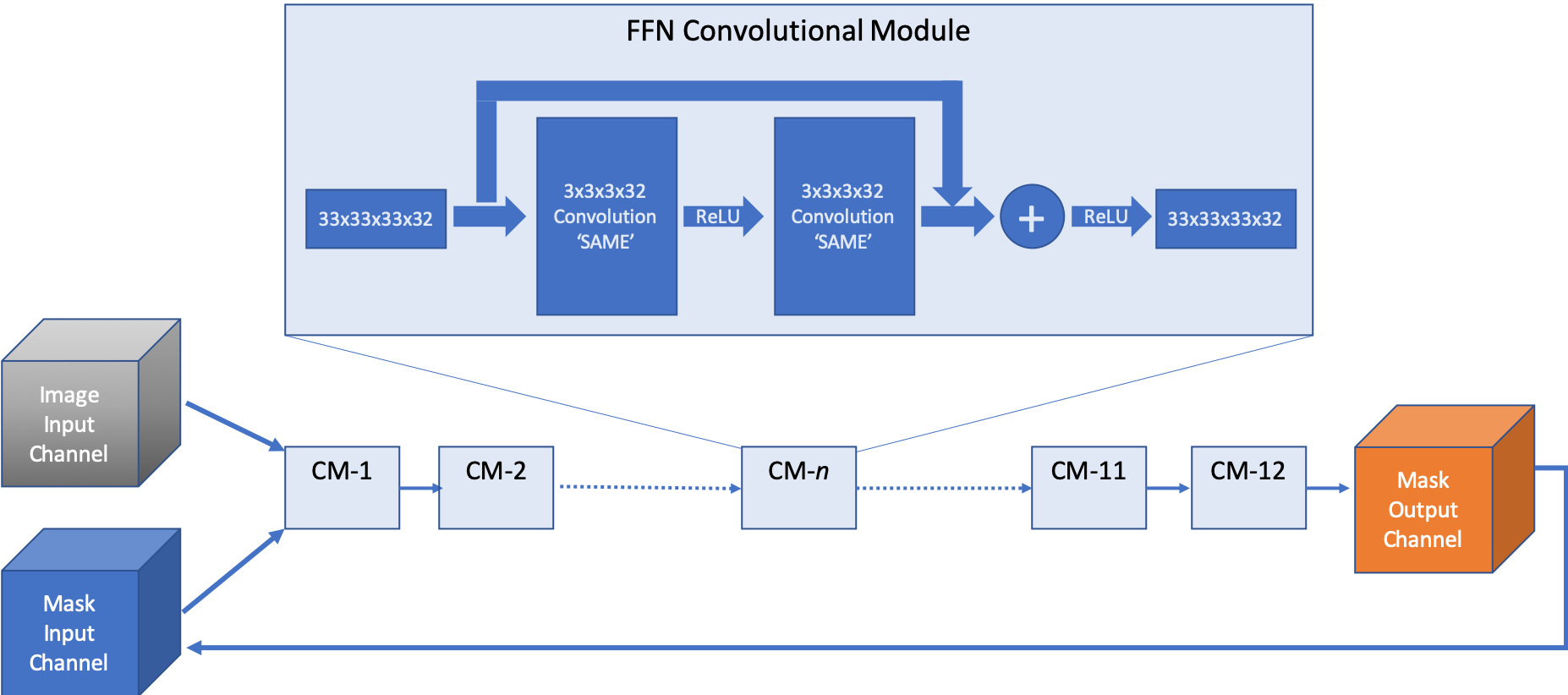
The flood-filling network (FFN) architecture has demonstrated leading performance for segmenting structures from this data. However, the training of the network is computationally expensive. The figure below shows the FFN’s workflow: 12 identical convolutional modules implement the operations shown in the top inset box. Mask output provides recurrent feedback to the FFN input.
In order to reduce the training time, we implemented synchronous and data-parallel distributed training using the Horovod library, which is different from the asynchronous training scheme used in the published FFN code.
We demonstrated that our distributed training scaled well up to 2048 Intel Knights Landing (KNL) nodes on the Theta supercomputer. Our trained models achieved similar level of inference performance, but took less training time compared to previous methods. Our study on the effects of different batch sizes on FFN training suggests ways to further improve training efficiency.
Results
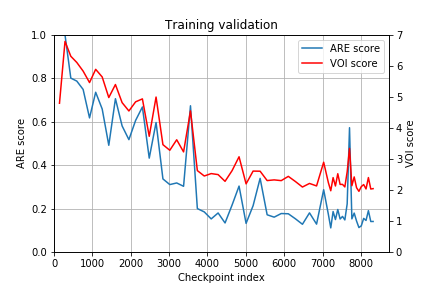
Our distributed training reaches 95% accuracy in approximately 4.5 hours using the Adam optimizer
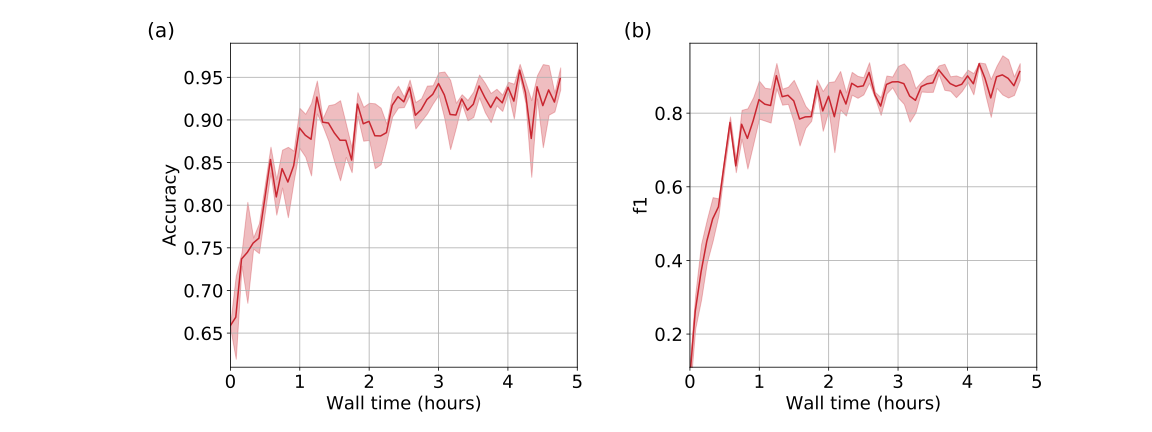
The trained model shows good results on the evaluation data.
The training performance achieves a parallel efficiency of about 68% on 2048 KNL nodes. 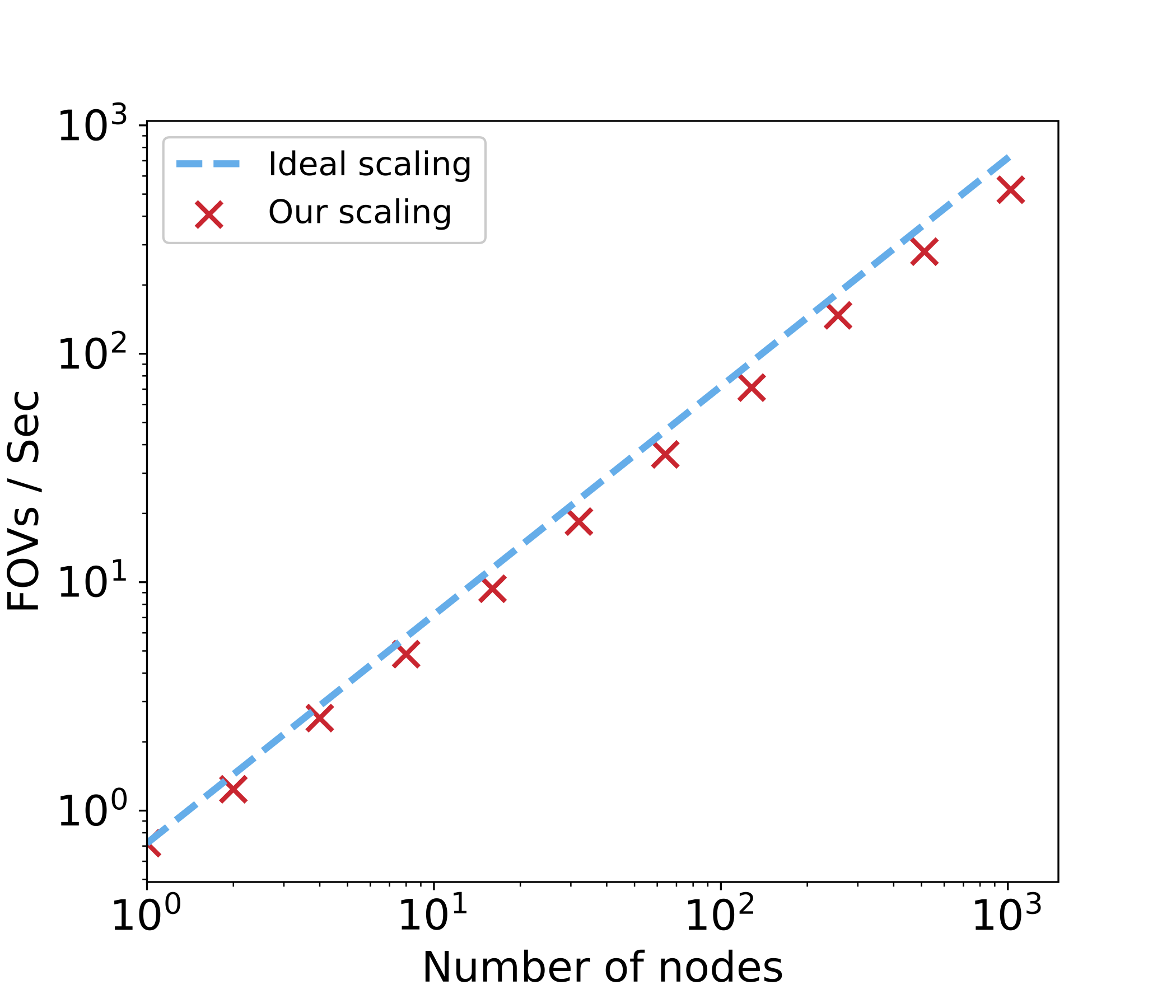
Methods
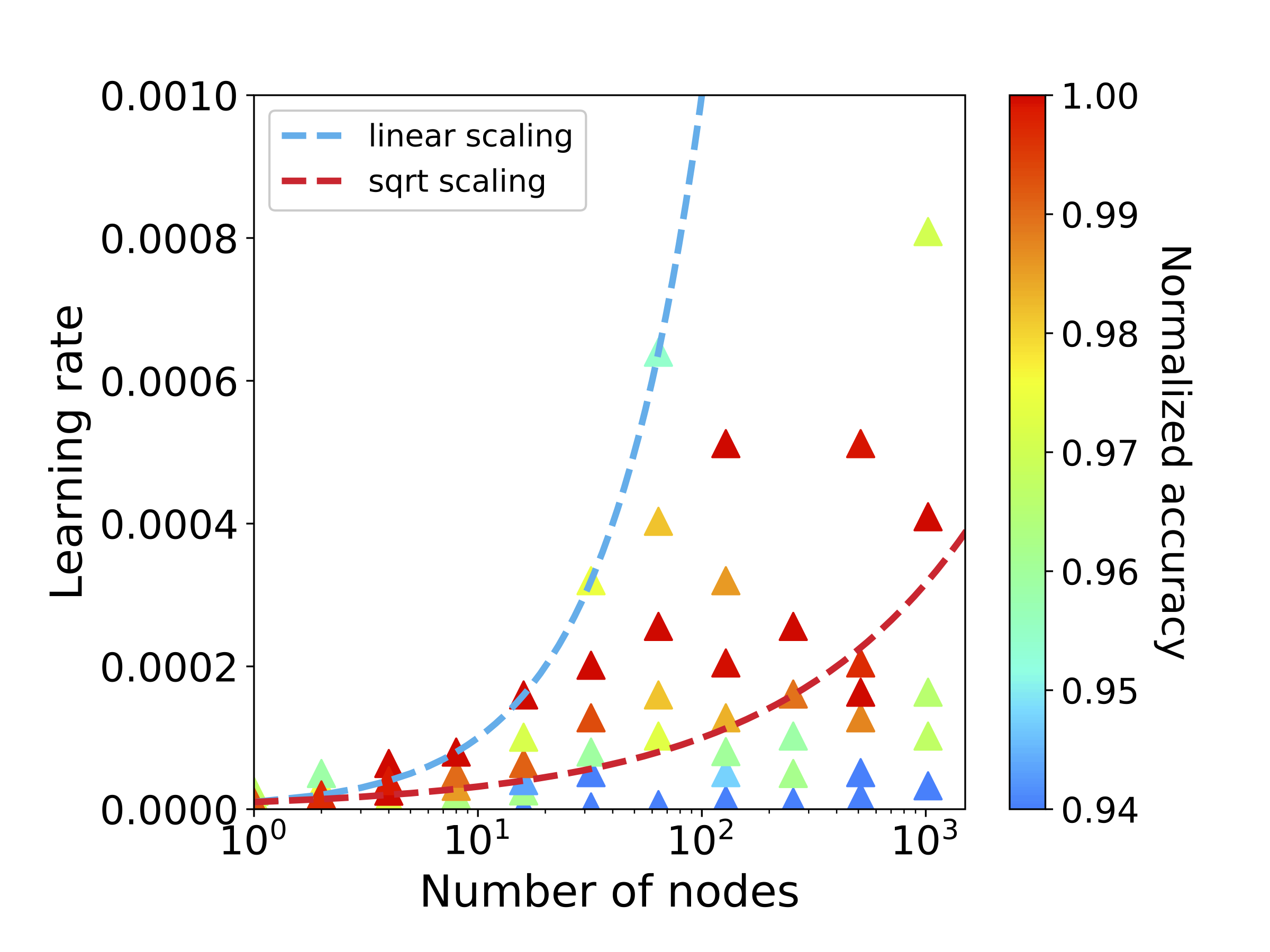
In order to reduce the training time, we implemented synchronous and data-parallel distributed training using the Horovod framework on top of the published FFN code. We demonstrated the scaling of FFN training up to 2048 Intel KNL nodes (131,072 cores) at Argonne Leadership Computing Facility (ALCF). We investigated the training accuracy with different optimizers, learning rates, and optional warm-up periods.
We discovered that square root scaling for learning rate works best beyond 16 nodes, which is contrary to the case of smaller number of nodes, where linear learning rate scaling with warm-up performs the best.
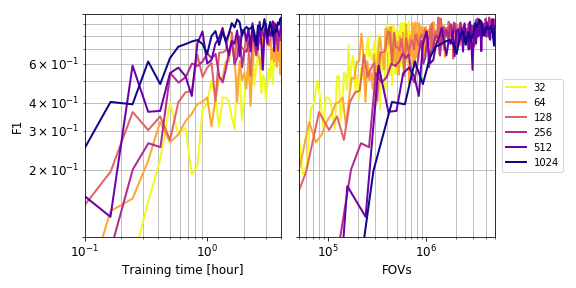
We also evaluate the tradeoff between training throughput and efficiency for large-batch training in the figure below, where we compare training runs with different batch sizes. On the left we compare F1 with wall time. On the right we compare F1 with total number of FOVs processed. Large-batch training is faster (left) to reach a specified level of performance, while small-batch training is more efficient (right).
Our work is an important step towards a complete simulation pipeline of the human brain, which could produce the same activity — connectivity patterns that produce stereotypical behaviors — seen on the wiring diagram.
Publication
Talks
-
W. Dong, M. Keceli, R. Vescovi, H. Li, C. Adams, E. Jennings, S. Flender, T. Uram, V. Vishwanath, N. Ferrier, N. Kasthuri, P. B. Littlewood, Scaling Distributed Training of Flood-Filling Networks on HPC Infrastructure for Brain Mapping, 2019 IEEE/ACM Third Workshop on Deep Learning on Supercomputers (DLS) at Supercomputing 2019 (SC19). (November 2019) View slides »
-
W. Dong, M. Keceli, R. Vescovi, H. Li, C. Adams, E. Jennings, S. Flender, T. Uram, V. Vishwanath, N. Ferrier, N. Kasthuri, P. B. Littlewood, Scaling Distributed Training of Flood-Filling Networks on HPC Infrastructure for Brain Mapping, 2019 Argonne Leadership Computing Facility (ALCF) Simulation, Data, and Learning Workshop: Success Stories of Science Applications Using Simulations, Machine Learning Tools and Data Science. (Invited; Ocotober 2019)